

序章
腹が減っては戦(勉強)はできぬ。
使い古された格言の胸に授業前に平太周の「爆盛油脂麺」(1,100円)を食べる。
これは大学生の頃、眠気を誘う三限前に誰もがやったことのあるルーティンであるが、まさか社会人になって同僚とそんなことをするとは生きていて思いもしなかった。
なんとこのメニュー同じ値段で200g-400gの間で麺の量を選ぶことができる(写真は300g、ネギTPG)

そしてさらにこの混ぜそば、には専用のトッピングセットが配布される「マスタード、タバスコ、マヨネーズ、青のり、七味、鰹節、酢」
ジャンクフードというにふさわしい設計だ。
同僚の言葉を借りるのであれば
「マスタードと酢をかければ、ハンバーガーに青のりとかつお節をかければ焼うどんに変わる。これはまさに未来の食事です」
さて、そんな大罪に浸っている暇もなく本日のメインイベント、立正大学の公開講座がまもなく始まる18:30-

立正大は大崎と五反田の間にある。
社会人になって誰が大学に行くか!とは考えず一度は行ってみることをお勧めする。
きっと学生時代の思い出が卒業した大学でなくても思い浮かんでくるだろう。(学食ボッチ飯をキメた思い出が湧き上がってきたようだ)
で、この企画は何なのかというと品川区と立正大学文学部が共催で企画した公開講座というわけだ。
全部で五回、テクノロジーから芸術方面まで幅広いトピックを扱いながら「ことば」について考えるというわけだ。
参加費は無料、であれば知が赴くままに参加する以外選択肢はない。

立派な講堂へ入場。写真は撮ってよいのか微妙だったので無いです。
一生懸命「ことば」で伝えます。
ステージに向かってすり鉢状に配置された赤い席。階段を下って前から二列目の真ん中へ着席
席にはまるで航空機の非常口座席を思わせる、ひじ置きに格納された小さな机を使うことができる。
開会に先立ち文学部部長の村上さんのご挨拶。これがなかなか心にきた。
言葉があふれるという「ことば」がある。 表現したことが内から湧き出てくるとするのであればそれは心の思いがあふれるということだ。
それはつまり生きていること=こころが積極的に動くことである。
一方でSNSに見られる誹謗中傷、生成AIから作られる立派な課題レポート。そこに自分の心を体現する「ことば」はあるか?
そしてもう一つ。
言葉にならないという、「ことば」があるようにこころの奥底に存在する言語化できない領域がある。
本公開講座ではここにも焦点を当てるために、最新テクノロジーから芸術家までのゲストスピーカーを招いた。
このコンセプトはなかなか面白いとおもった。私のこころはすでに動いているよ。
今日は書いて書いて書きまくる!
ゲスト、川添愛先生
第一回目のゲストの先生は川添先生。
専門は理論言語学であるが、言語学から発展して自然言語処理など近年ホットなトピックであるAIにも幅広い知見をもっていらっしゃるようだ。
言語学と情報科学。編集長が大好きな二大分野が専門であるというだけでワクワクする。
特に興味がわいたのは難しくなりがちなコンピュータの話を、物語形式で紹介する書籍を執筆していることだ
私はある概念をアナロジーで説明することが大好きだ。
もちろんある程度の厳密さは欠けるが、例えてみることで改めて共通点と相違点が明らかになって理解が深まることは往々にして多い。
AIの基本的な仕組み
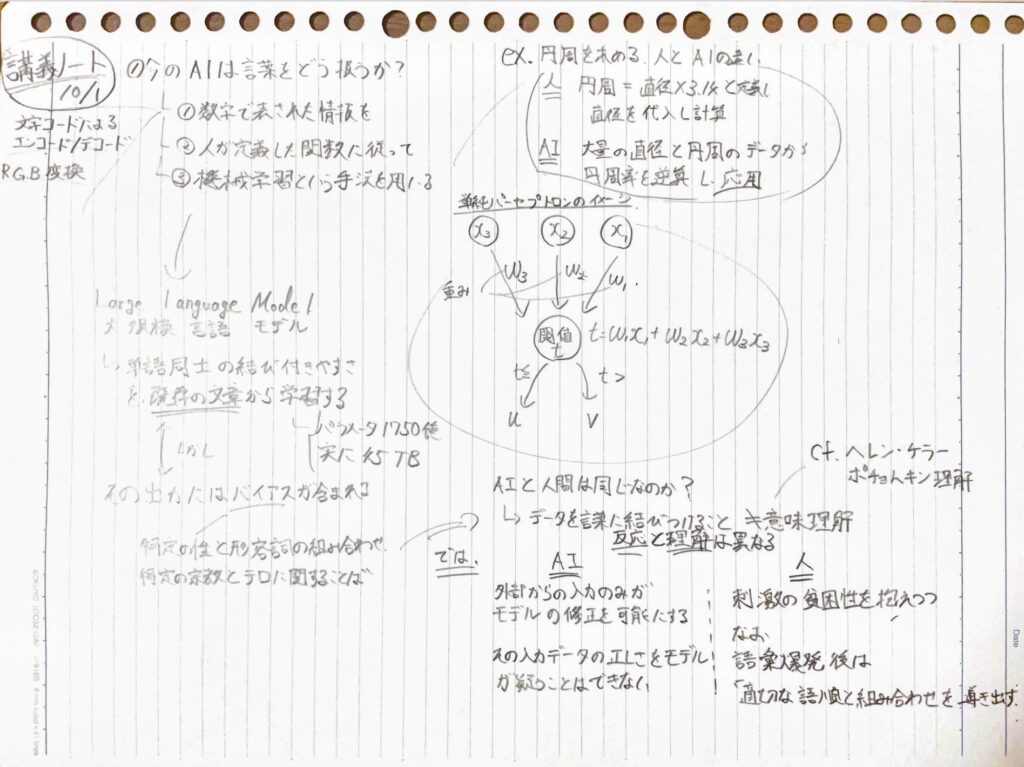
講義はAIとよばれるものの、根幹をなす技術について解説するところから始まった。
AIとは三つの要素からなる
- 数であらわされた情報を
- 人間が決めた課題をこなす関数に従って
- 機械学習という技術を用いて計算する。
なかなかシンプルで的確な説明だと感じました。
画像も、文字も、音声もデータ(0か1一定の電圧以上かそれ以下か)に変換するというステップを嚙ませれば扱うことができてしまう。
もっとも簡単な例として単純パーセプトロンの紹介が行われた。
もちろんこのモデルの厳密な解説はこのブログの役目ではないので割愛。
まぁ、入力されるデータをもとに出力すべきデータが決まる。
入出力でそのデータが何を表す(人間が理解できる画像なり、文字なり)かは対応付けられているということだ。
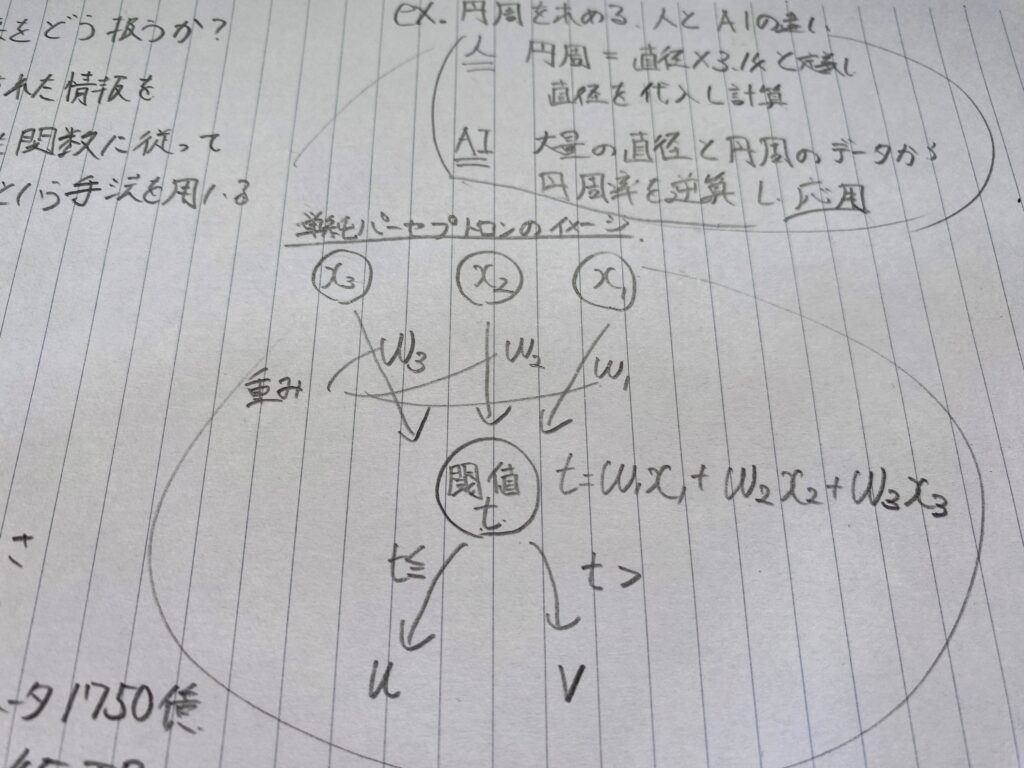
で、いま主流となっているのは、層を何重にも深くしたディープラーニングというモデル。
正解と定義したデータに近いような出力が出せるような関数のパラメータを、大量のデータから学習することでより良いモデルが決定していくと。
ことばに関する生成AI(例えばChat GPT)で使うモデル(関数)を大規模言語モデルという話で十分だろう。
AIは自然な文を作ってくれる。ではAIと人間は同じか?
答えは当然No、少なくとも今の段階では。
なぜならばチャット生成AIがやっていることは私たちが入力した文章をデータに変換して、過去に得られたデータから予測できる最も確からしい語の組み合わせを出力しているからに過ぎないから。
そこに意味理解が伴っているかどうかというのが一つのポイントということだ。

では意味理解とは?AIと人を隔てる特徴は何かという話になる。
AIにとって入出力を決める根幹をなすモデルは、外からの新しい入力が恣意的に入らなければ修正されない。加えてその入力が正しいかどうかはモデル自信が疑うことはないということだ。
一方で人間は外部からの入力が(少なくともAIのモデルを訓練するときよりは)少ないにもかかわらず、一定の年齢を超えると言語を使う能力が飛躍的に向上する。
※講義では人間の言語習得において外部(親)からの修正が少ないことにを表す「刺激の貧困」というノーム・チョムスキーが提唱した概念への言及があった。
また、刺激が少なくともある一定レベルを超えると扱える言葉の量や、正しい語順で文を作ることができる現象をさして語彙爆発と表現していた。こちらはチョムスキーとは直接は関係ないものの、意味理解ができる人間だからこそ言語能力の目覚ましい発展がみられることを強調するための表現と理解している。
そして意味理解を伴はない見せかけの理解を「ポチョムキン理解」と表現するようだ。
また脱線するが編集長はポチョムキンと聞くと「戦艦ポチョムキン」というプロパガンダ映画を想起する。家に帰って調べてみれば言及されているポチョムキンはどうやら同じ人物のようだ。 ※申し訳ないがポチョムキン周りに関しては幾度となく別サイトで解説されているのでそちらを参照していただきたい。
ふむふむ。AIと人間は違うのね~確かに!と納得しそうになっていたが、、、
いや自分もポチョムキン人間だったのでは?とも思う。
そうそれは、中学受験の時にギザギザの海岸線を見たら恐ろしく速い速度で「リアス式海岸!!」と回答する幼き編集長のこと。
あの時私は、なぜリアスという名前なのか、実際の海岸線はどう見えるか考えたこともなかった。
社会で高得点をたたき出すために、ギザギザの海岸線のイラストにはリアス式海岸と回答すればいい。そう思っていた。
それはまさに反応、いや反射ともいうべきか?そこに意味理解はあるんか?
意味理解という概念も「何をもって意味理解したのか」という点にはもう少し考えを深める必要がありそうだ。
先生の見解
いろいろと生成AIの仕組みから人間への影響について、様々な文献への言及を踏まえながら講義は終盤をむかえる。
最後のメッセージは、「その知識について深い洞察をすでに持っているのであればAIを使いこなすことはできる。ただ、あまりよく知らないことに対してAIの出力に頼りすぎることは少し危険」と理解している。
結局AIが出してきた答えに対して、正しく疑うことができる(それができる人はAIがなくても少なくとも、その分野に関しては十分な知識がある)
これ、つまり出力された答えの正しさや、その答えが出力されるために使われた入力の正しさを疑うことができる人こそが「人が人足りうる特徴」を保持し、今のAIと付き合っていく解の一つを導くことができるということだろうか。
会社では基本脳死で「Prepre RFI ? It's waste of time(しかめ面), Use AI(ドヤ顔) !」 といわれることが多い。
世間的にもAI使えば仕事効率化!みたいな風潮もある中でやや慎重な姿勢を見せる専門家を目の前にまた何か思考が働いた気がする、、
感想
あっという間に一時間半がたち、第一回の講義は終わった。
大学時代に統計を勉強した流れで、機械学習に関してはほんの少しだけ勉強したことがあった。
そんな意味でAIの仕組みという点では既知の内容が多かったように思う。一方でそれがどう人間と異なるかという、「ことば」の理解の仕方という切り口ではあまり考えたことがなかった。
特に反応と理解は違うという言葉にはハッとさせられるところがあった。
全五回、これからの展開が非常に楽しみだ。

